Digging for trusts — Revolutionary trustable information extraction system
“It’s time to ditch that unexplainable information extraction” — Some Anonymous Cinnamon AI Researchers said.
What is this about?
As part of Cinnamon’s mission, we study Expertise Distillation to extend human potential: AI systems that are smart enough to augment even the experts with distilled expertise. Systems that can perform specialized expert-level tasks.
There are many ways to augment an expert’s capacity: Enhancing speed, removing repetitive processes, etc. In this article, we are talking about a trustable information extraction system that can be used for even experts who seek empowerment. Anyone can implement a pocket version of information extraction AI today: given a dataset, an OCR model, a text-line detection model, and some Key-value Extraction model.
So why do we have to go beyond that?
Cram’s story
It was a Tuesday morning, a week after Cinnamon’s Flax user — Cram applied the system on all of his client’s cases. As a bank compliance manager, Cram used to have to check all clients’ files to determine whether they are eligible to be given a loan for some specific purpose. Cram is now enjoying coffee in his office while reading a philosophical book for all the time he has earned by this technological upgrade. At 9 AM, however, Cram has suddenly received a call from his manager, speaking in a frightening voice — 5 of his clients had invalid identities or assets, this has only been known after an enormous withdrawal amount at their accounts (in one case, it was over $10,000,000, a very big number).
Guess what? That Flax version’s decision accuracy reached what may be called Deep Learning limitation: 95% of Accuracy.
When it comes to information extraction systems, they stop at giving us answers: the name of the applicant or the loan amount. However, just answers for Cram’s case is not really enough: There are high stakes and risks in any applications, and he requires a high level of reliability due to the fact that the extracted fields will be used further for auditing, analyzing, and affect the decision making of subsequent steps.
This is where we want to step in: the job itself is easy for Cram, but he wants to make sure that no basic mistakes are made. While it is not yet possible to give Cram the ability to do that, we give a partial answer to another question: How can we trust the Extracted results?
Cram need a trustable information extraction system
What we are introducing is a novel information extraction system that allows clients and users like Cram to see the logic behind each of the decisions and predictions, making it safer for highly-risked cases.
Thus, we believe it is absolutely necessary to provide our clients a means to see the level of reliability our system may achieve, having the model’s accountability and uncertainty to be measurable; it can be used for debugging, understanding under which circumstances, which examples the extraction may fail, such that for confident cases, we should be able to trust the system completely.
By applying this system, Cram can see exactly which form can be left for a fully-automated process and the progressiveness of the information extraction.
To really help Cram, we would take investigations in qualities of a good explainer, which are:
- Provide good Quality of Explanations:
— Help users with Current tasks.
— Help users with Future tasks.
— Accumulate Long-term knowledge. - Be Predictive — explanations aligned with Expectations.
- Be Robust — not sensitive to noise.
- Have Fairness — against discrimination.
Information Extraction via Explained Graph Neural Network
We start with the output from DIX (Document Information Extraction):
Given the Flax Scanner consisting of DOR & DIX part, we aim to provide some human-understandable explanations which fulfill the above characteristics. As we can preprocess the documents into text-line graphs, we’re able to perform Information Extraction as graph-based models using GCN; details can be found in our previous article.
Considering what has been done, there have been a few usable advantages in the context of explaining result.
- Graph-input itself is already somehow traceable.
- Other explanation methods may be applicable on GCN models with Modification.
Unlike LIME or other model-agnostic methods, viewing explanation on this type of representation is much easier and with fewer noises:
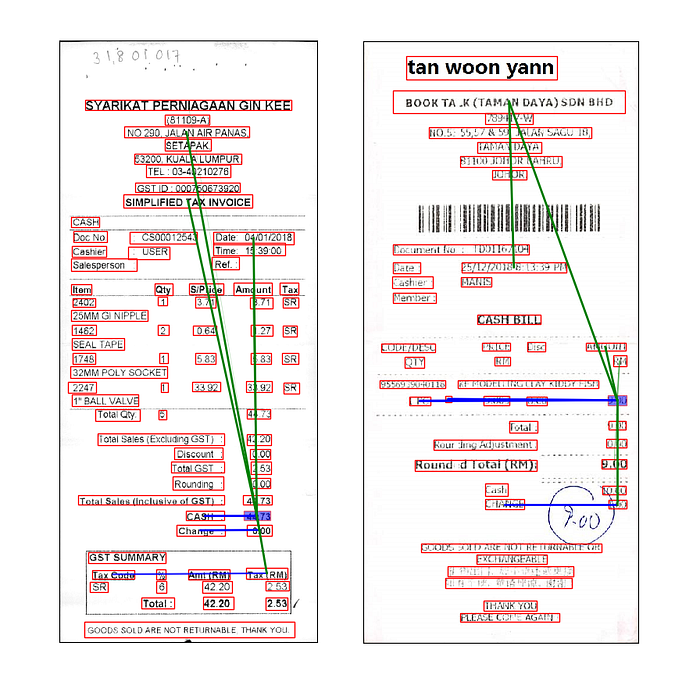
As Graph-inputs are easily understandable towards humans, explanations based on Graphs are therefore already predictive: they can inform us how information propagates from text-line to text-line. Robustness for explanations is also achieved, since the source of noise in data is limited: most images’ noises are removed at the DOR phase. Instead of per-pixel / super-pixel level explanation, we have text-line influencing level, and from the output, we can see:
- Exactly from where / which fields does the inference engine start gathering information.
- How strong the influence is via the strength of the arrows.
This gives us sense even when GCN prediction is wrong so we may modify it later:
From this image, we see that the “28.90” is the main cause of the wrong prediction for the field of “total”, so we may add simple rules such as “right of ‘total’” to correct just this case. It will not directly allow users to modify the models, but at least we understand when the model would output sub-standard predictions.
So, how can we ensure the quality and fairness of explanation, in order to validate the trustability of Extracted results?
Explanations as Subgraph Highlight
Recall that we may obtain the adjacency matrix representing the spatial relations between text lines in the same manner as in the previous article. This is the overview of GNN Explainer applied in our case:
As we all understand that: Information Extraction data are highly task- / domain-specific, we would expect the corresponding feature for which AI models behave on different domains may align with human behavior patterns and domain knowledge. And if they DO align, humans might be more likely to regard the system trustable.
And to verify whether the highlighted features do contribute, we perform explanations on concrete / discretized feature representation, it is still regarded way less effectively than substructural highlights for human eyes. But it will work, for now.
In the end, with all of these explanations and depictions, we only wish to say one thing: It’s time to ditch that unexplainable information extraction system.
Author: Dini & Marc
(Ching-Ting Wu & Nguyen Thanh Dat)
Reviewer: Toni, Benji, Neo
References
[1] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why should I trust you?” Explaining the predictions of any classifier. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 13–17-Aug, 1135–1144. https://doi.org/10.1145/2939672.2939778
[2] R. Ying, D. Bourgeois, J. You, M. Zitnik, J. Leskovec. GNNExplainer: Generating Explanations for Graph Neural Networks, Neural Information Processing Systems (NeurIPS), 2019
