Finding Objects In Document Images
1. Overview
Let’s start with an observation: administrative documents are playing an important role as a tool for transferring, storing, and searching for data.
Indeed, these administrative documents are generated when doctors write medical receipts for patients, clerks give invoices to customers, and also used as an intermediate measure before stored in a digital database.
A wide range of professionals will usually need some kind of Information Extraction (IE) from these administrative documents: doctors, customers, financial clerks, researchers, sales, etc.
Since there exists such a wide range of users, we see that IE may require a very high level of precision, and also a certain level of expertise to verify the extracted information.
At Cinnamon, we construct Flax, it is designed for extracting relevant information from these administrative documents:
Flax can read medical receipts, invoices, insurance forms, etc. in an accurate and efficient manner.
Using a deep-learning-based pipeline which will be discussed in this series, Flax can be retrained easily from a small amount of annotated documents.
We hope that by constructing this product, doctors and pharmacists may spend more time learning, researching, back-office members spending more time examining and extracting from digital data and improve overall productivity.
In the following series of blogs, we will walk through each component of our Flax Scanner system to examine its key performance and then one interesting feature that we have developed: explainability.
2. Flax Scanner:
Flax Components
We have seen that some use cases of Flax may require a very high level of accuracy while it is used by various clients.
Thus, it is essential for the Flax to have the capability to deal with these various formats, layouts while maintaining a high level of accuracy for each of the formats.
Our Flax scanner system, as a whole, can be arranged into two main modules respectively:
- Document Object Detection (DOR) The general modules, used across all types of documents. It takes input as images and output text lines’ locations (Layout) and their text contents (OCR).
- Document Information Extraction (DIE) The task-specific module, it used a small number of text lines location and contents to identify which is the relevant information that needs to be extracted.
We cover these modules first before delving into our essential extra components (The Explainer) later in the series.

3. Decomposing Image Structure with DOR modules:
It is a common question we encountered by engineers and researchers: Why do we have to decompose document image first before performing information extraction (IE)?
Indeed, it is tempting to leverage object detection technologies like Faster RCNN [2] or YOLO [3] for a holistic architecture, but we did not do that.
We want Document Object Detection to be a general module that works with any documents since each document and each format requires specific fields extractions: medical receipts needs medicines’ name, invoices need items’ values, etc.
So it has to have an intermediate representation that covers all of these,
upon “decomposing images”, the Task’s goal is to detect, localize, and recognize any useful pieces of information for further Key-Value extraction.
Problem Formulation
We define Document Object Recognition as follows: Given a document, detect all defined objects (stamps, tables, icons), defined by their locations (x, y, w, h) and all text lines, defined by a tuple of (x, y, w, h, text), referring to text lines’ coordinates on the documents, their width, height, and their textual content.

In our specific case, the shape and locations of each object are handled by layout sub-module, and converting from text lines location and image to textual content is handled by optical character recognition (OCR module).
Layout detection
As described in the previous subsection, the layout modules are used to localize intermediate components of a document such as a table, stamp, and text lines. It takes input as an image and output the coordinates and dimensions of these components.
Under scenarios in the reality, document’s layouts vary in shapes, sizes, image quality, and lighting conditions, making it a challenge for normalizing images into a specific intermediate format.
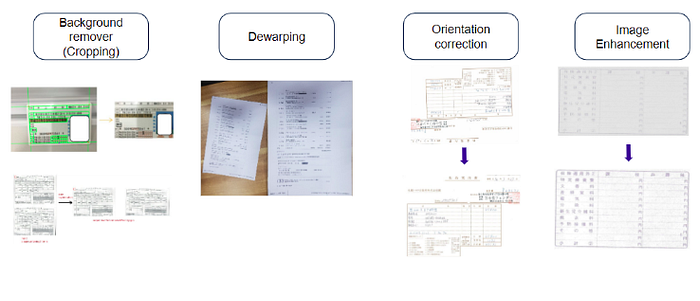
However, as we progress and apply augmentation techniques as well as various functions (de-wrapping, enhancing contrasts, orientation corrections), we achieved high-performance modules (around 0.9 Intersection over Union) in detecting essential components such as text regions, stamps, or tables inside the document images, even under varied lighting and background conditions.
OCR
The locations achieved from the Layout module are then used to cropout each text line image for the OCR module to convert it into textual data.
We emphasize that OCR technology has been developed for a long time: Researchers have tried using projection profiles as well as hand-crafted features to transform images into text.
At Cinnamon, we leverage state-of-the-art deep learning architectures to obtain the highest possible performance and precision under varied conditions.
Aside from the aforementioned challenge in lighting, shapes, and fonts which affects both layout and OCR, in order for it to really handle real-world cases, we also have to deal with the hand-written text as well as printed text:
- Printed Character: They are digital characters and often generated by a standard printer machine. Moreover, the quality of the image(blurred or different style of fonts) at the character level might be a big challenge in this character type.

Handwritten Character: They are much more difficult to recognize than printed characters since people have various handwriting styles.

Network architecture:
Researchers in the AI domain has developed multiple different neural network architecture imitating the human brain for solving a specific task for recent years. Such popular networks to handle images and texts information which we can exploit and use it in our systems are Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). In the proceeding sections, we start by describing these architectures under their respective orders.

As the input to Document Object Recognition (DOR) is an image, CNN is employed to automatically transform this image into a set of feature maps. Proceeding through convolution layers, visual cues are aggregated in each of the feature maps, where the final one is forced to output the mask of where text lines are located. Within the scope of this blog, we only focus on the most typical component of the document image that is text lines. This process is called text line segmentation.
For the specific architecture of convolutional networks, AR-UNET is a sophisticated architecture for segmentation task:
- AR-UNET: Traditionally, UNet(paper) is a popular neural network with two different paths forming a U-shape: one path is used for contracting and the other is for reconstructing the visual information. Attention-Residual-Unet(paper) which belongs to Unet family have new residual connections(paper) as well as an attention mechanism(paper) to focus on interesting regions. This architecture is introduced in a paper named “A Two-Stage Method for Text Line Detection in Historical Documents” to perform text line localization.
- AR-UNET is leveraged in our system due to its ability to efficiently handle the multiscale document images. Document images are downscaled into different versions and all are fed into the network for aggregating mutual information, training, and performing pixel-wise classification for the image with 3 classes: baselines, separator, and other.
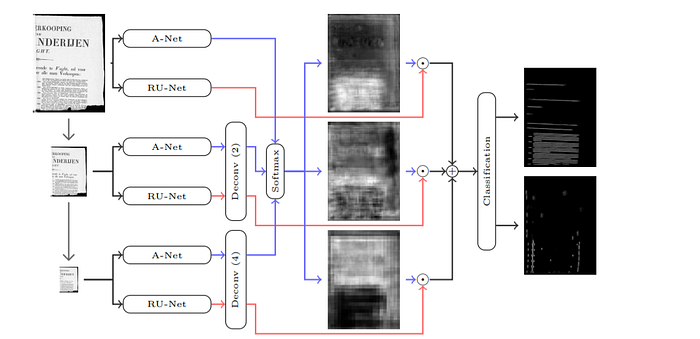
After applying segmentation (layout detection) on the images, we would expect to obtain text boxes’ locations. But these still only feature maps (we can see it as a stack of images), to convert these to textual representation, an Optical Character Recognition (OCR) process has to be performed. This is where Convolutional Recurrent Neural Network (CRNN) comes in.
- Convolutional Recurrent Neural Network (CRNN): In order to convert from masked image portion into textual representation, CRNN(paper) is used for performing character recognition. This architecture is a composition of both CNN and RNN along with a special final layer using a probability model to perform character prediction called Connectionist Temporal Classification.
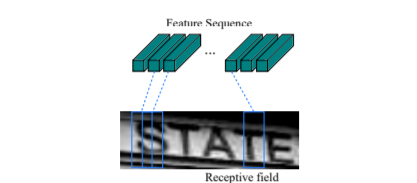
By considering each sliding rectangle in the feature sequence potentially containing one character, the RNN will learn the connection among these sequences in both directions: forward and backward. Finally, prediction of character is then passed through the CTC probability model to calculate the confidence score of all potential sequence which can exist in the document image and then determine the final correct character sequences. The complete flow of CRNN architecture is illustrated in the following image:

4. Conclusions:
In this first article, we have walked through the overview of Flax Scanner. We also listed down some challenges that a solution might encounter and discussed some of the promising solution tacking with these problems on the Document Object Recognition components. For further information on the other components and our system, we hope to see you in the upcoming blog posts.
References:
[1] Grüning, T., Leifert, G., Strauß, T., Michael, J., & Labahn, R. (2018). A Two-Stage Method for Text Line Detection in Historical Documents. https://doi.org/10.1007/s10032-019-00332-1
[2]Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
[3] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016-Decem, 779–788. https://doi.org/10.1109/CVPR.2016.91
— — — —
Written by: Zed — AI Researcher Intern
Consultant team: Marc, Toni, Ace, Sonny, and Ching-Ting Wu.
